Exploring Diffusion Transformers: The Next Leap in Image Generation
Introduction
AI-generated images are now everywhere, fueling creativity in social media, advertising, design, scientific research, and even memes. The technology powering these visuals has evolved at a breathtaking pace. Not long ago, Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) were the gold standard for generative image models. Today, diffusion models have taken the lead, setting new benchmarks for image quality, diversity, and flexibility.But the story doesn’t end there. A new hybrid approach is emerging: Diffusion Transformers (DTs). By combining the strengths of diffusion models and transformer architectures, DTs are poised to become the next leap in generative AI. What exactly are Diffusion Transformers? Why are they important, and what innovations do they bring to the table? Let’s explore.
The Evolution of Image Generation
GANs: The Adversarial Revolution
The introduction of Generative Adversarial Networks (GANs) by Goodfellow et al. in 2014 marked a turning point in generative modeling. GANs consist of two neural networks, the generator and the discriminator, locked in a creative adversarial game. The generator strives to produce images indistinguishable from real ones, while the discriminator attempts to tell real from fake.
Pros:
Capable of producing highly photorealistic images, often indistinguishable from real photographs.
Enabled creative applications such as deepfakes, upscaling, and style transfer, which have had a profound impact on digital art and media.
Cons:
Training is notoriously unstable and sensitive to hyperparameters, often requiring careful tuning and luck.
Prone to mode collapse, where the model generates limited varieties of images, reducing diversity and creativity.
Use Cases: Art generation, face synthesis, video creation, style transfer, and even the creation of synthetic datasets for research.GANs have been instrumental in pushing the boundaries of what machines can create, but their limitations have spurred the search for more robust and flexible generative models.
VAEs: Probabilistic Latent Spaces
Variational Autoencoders (VAEs) take a different approach, encoding images into a latent space and decoding them back, all within a probabilistic framework. This allows for smooth interpolation between images and stable training.
Pros:
Stable and interpretable training process, making them easier to work with than GANs.
Good for interpolation and semi-supervised learning, as the latent space is continuous and meaningful.
Cons:
Generated images often lack sharpness and fine detail, resulting in outputs that can appear blurry or less realistic.
Use Cases: Representation learning, data compression, generative modeling, and anomaly detection.VAEs have been valuable for understanding data structure and for applications where interpretability and stability are more important than photorealism.
Diffusion Models: The New Standard
Diffusion models, such as DDPM, DALL-E 2, Imagen, and Stable Diffusion, generate images by gradually denoising random noise through a Markov process. This process is inspired by non-equilibrium thermodynamics, where information is gradually lost and then reconstructed.
Pros:
Exceptionally stable training, less prone to mode collapse and vanishing gradients.
High-resolution, diverse, and robust outputs, often surpassing GANs in both quality and variety.
Flexible for conditional generation (text, images, sketches), making them suitable for a wide range of creative and practical applications.
Cons:
Sampling is slow and computationally intensive, often requiring hundreds or thousands of steps to generate a single image.
Use Cases: Text-to-image generation, inpainting, image editing, upscaling, and even video generation.
How Diffusion Works: Step-by-Step
Start with a real image.
Add Gaussian noise in steps until the image becomes pure noise.
The model learns to reverse this process, denoising step by step to reconstruct the image.
This iterative process allows diffusion models to generate images with remarkable detail and diversity, but the computational cost has motivated further innovation.
Why the Shift Toward Diffusion?
Diffusion models have become the preferred approach for several compelling reasons:
Stable Training: They are less prone to mode collapse and vanishing gradients, making them more reliable than GANs. This stability allows researchers to train larger and more complex models without the same risk of failure.
Diversity: They offer better mode coverage, resulting in more varied and creative outputs. This is crucial for applications where novelty and diversity are valued, such as art and design.
Photorealism: Capable of generating high-resolution, detailed images that rival or surpass GANs, making them suitable for commercial and scientific use.
Flexibility: Easily conditioned on text, images, or other modalities, making them suitable for a wide range of tasks, from text-to-image generation to image editing and beyond.
Scalability: Can handle large datasets and models, making them suitable for industrial-scale applications and research at the frontier of AI.
The combination of these advantages has led to rapid adoption and further research into making diffusion models even more powerful and efficient.
What Are Diffusion Transformers?
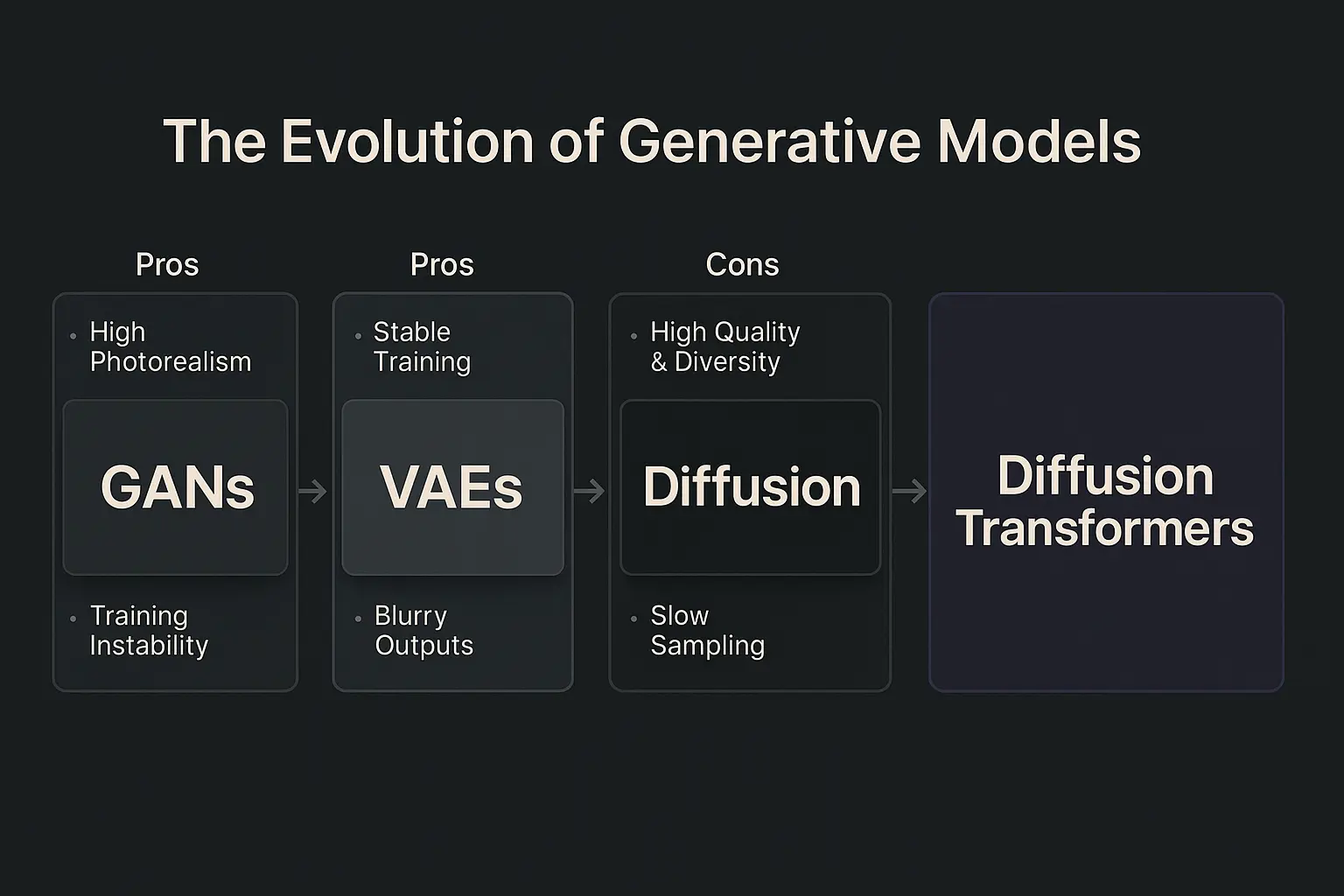
The Basics
Diffusion Transformers (DTs) are a new class of generative models that merge the denoising power of diffusion models with the global context and scalability of transformer architectures. Transformers, originally designed for natural language processing (NLP) by Vaswani et al., have since revolutionized vision (ViT, Swin), audio, and multimodal tasks. Their self-attention mechanism allows them to capture long-range dependencies and global structure in data, which is essential for generating coherent and complex images.
Why Combine Diffusion and Transformers?
Expressiveness: Transformers can model global structure and context, which is crucial for generating images that are not only realistic but also semantically meaningful and coherent.
Scalability: Transformers scale efficiently to large models and datasets, leveraging modern hardware such as GPUs and TPUs for parallel computation.
Flexibility: They can easily integrate multiple modalities (text, audio, images) within a unified architecture, enabling cross-modal generation and multimodal applications.
Unified Architecture: Transformers can encode, decode, and condition on various inputs, making them highly extensible and adaptable to new tasks and data types.
By combining these strengths, Diffusion Transformers are able to push the boundaries of what generative models can achieve, opening up new possibilities for creativity and innovation.
The Transformer Revolution
Transformers have not only transformed NLP but have also made significant inroads into computer vision (e.g., Vision Transformer [ViT], Swin Transformer), audio, and multimodal learning (e.g., CLIP, Flamingo). Their self-attention mechanism enables models to maintain coherence and context across entire images or sequences, which is especially valuable for generative tasks. This ability to model long-range dependencies and relationships is a key reason why transformers are so effective in generative modeling.
How Do Diffusion Transformers Work?
The Diffusion Process
The core idea behind diffusion models is to gradually add noise to an image over many steps, transforming it into pure noise. The model is then trained to reverse this process, step by step, to reconstruct the original image. In Diffusion Transformers, the denoising network is a transformer rather than a traditional convolutional neural network (CNN).
Forward Process: A Markov chain adds Gaussian noise to the image at each step, progressively destroying the original structure.
Reverse Process: The transformer predicts either the noise or the clean image at each step, learning to invert the process and reconstruct the image from noise.
This approach allows the model to learn a powerful generative process that can produce high-quality images from random noise, conditioned on various inputs such as text or other images.
The Role of Transformers
Traditionally, diffusion models used CNNs (like U-Net) for the denoising step. Diffusion Transformers replace this with a transformer, which brings several advantages:
Global Attention: Captures relationships across the entire image, not just local patches, enabling the generation of images with coherent global structure.
Better Text Integration: Improved prompt-based generation, as transformers can naturally handle text and image embeddings together, making them ideal for text-to-image tasks.
Multimodal Capabilities: Easily extend to text, audio, and other modalities, enabling cross-modal generation and richer, more interactive applications.
Architectural Variants
ViT-style: Images are treated as sequences of patches, similar to words in a sentence, allowing the transformer to process images in a way analogous to text.
Hybrid: Combines CNNs and transformers, using CNNs for early or late layers to capture local features and transformers for global context.
Pure Transformer (e.g., DiT): The entire denoising network is a transformer, replacing U-Net completely and leveraging the full power of self-attention for image generation.
Training and Sampling
Training: The model predicts noise at each step, minimizing a loss function (such as L2 or variational loss). This process is resource-intensive and requires large, high-quality datasets, but it enables the model to learn a robust generative process.
Sampling: Generation starts with noise and denoises iteratively. This is typically slow (requiring hundreds of steps), but new fast sampling techniques are emerging to make the process more efficient.
Fast Sampling Techniques
DDIM (Denoising Diffusion Implicit Models): Allows for deterministic sampling with fewer steps, speeding up generation and making real-time applications more feasible.
Distillation: Compresses the model for faster inference, reducing the computational cost and enabling deployment in resource-constrained environments.
These advances are making diffusion models more practical for real-world applications, where speed and efficiency are critical.
Conditioning and Control
Text Conditioning: Uses text embeddings (from models like CLIP or T5) for prompt-based image generation, enabling users to generate images from natural language descriptions.
Other Modalities: Can be conditioned on sketches, semantic maps, audio, or video, allowing for a wide range of creative and practical applications.
Multimodal Integration: Transformers excel at integrating multiple modalities, enabling cross-modal and conditional generation, such as generating images from audio or combining text and image inputs.
This flexibility makes Diffusion Transformers a powerful tool for artists, designers, researchers, and anyone interested in generative AI.
Key Innovations and Advantages
Diffusion Transformers bring a host of innovations and advantages to the field of generative AI:
Image Quality: Achieve higher fidelity, better global structure, and fewer artifacts compared to previous models, making them suitable for professional and commercial use.
Multimodal Generation: Capable of generating images, audio, video, and cross-modal content, opening up new possibilities for creativity and communication.
Scalability: Efficiently handle large datasets and leverage modern hardware for training and inference, enabling the development of large-scale generative models.
Flexibility: Support a wide range of tasks, including inpainting, super-resolution, conditional generation, video synthesis, style transfer, and data augmentation, making them versatile tools for many industries.
Robustness: Less prone to mode collapse, more robust to adversarial attacks, and capable of producing diverse outputs, increasing their reliability and utility.
Transfer Learning: Can be pre-trained on large datasets and fine-tuned for specific tasks, enabling rapid adaptation to new domains and applications.
Interactivity: Support user-guided editing, feedback loops, and interactive generation, empowering users to shape the creative process and achieve their desired outcomes.
Real-World Examples and Applications
The impact of Diffusion Transformers is already being felt across a variety of domains:
Art & Design: AI-generated art, concept design, and advertising campaigns are leveraging DTs for creative inspiration and production. Artists can use these models to explore new styles, generate ideas, and even collaborate with AI in the creative process.
Science & Medicine: Used for data augmentation, medical imaging, and scientific visualization, helping researchers generate synthetic data and visualize complex phenomena. For example, DTs can create realistic medical images for training and research without compromising patient privacy.
Accessibility: Generating images for visually impaired users, creating alt text, and translating language into images to improve accessibility. This can make digital content more inclusive and accessible to a wider audience.
Industry: Product design, marketing, prototyping, and e-commerce are benefiting from rapid, high-quality image generation. Companies can quickly generate product images, prototypes, and marketing materials, reducing time-to-market and costs.
Education: Content generation, simulations, visual aids, and interactive learning experiences are being enhanced by generative models. Educators can use DTs to create engaging and personalized learning materials, simulations, and visualizations.
These applications demonstrate the transformative potential of Diffusion Transformers across diverse fields, from art and entertainment to science and industry.
Challenges and Open Questions
Despite their promise, Diffusion Transformers face several significant challenges:
Computational Cost: Training and inference require substantial computational resources, often necessitating large clusters and significant energy consumption. This raises concerns about accessibility and environmental impact.
Inference Speed: Real-time generation remains a challenge, though fast sampling techniques are making progress. Achieving low-latency, high-quality generation is essential for interactive applications.
Data Requirements: Large, high-quality, and well-curated datasets are essential, raising concerns about data bias and representation. Ensuring diversity and fairness in training data is critical to avoid perpetuating biases.
Interpretability: These models are often black boxes; while attention and denoising visualizations help, building trust and understanding remains difficult. Developing tools and methods for interpreting and explaining model behavior is an active area of research.
Controllability: Achieving fine-grained control over outputs (such as object placement or style) is still an open problem, and prompt engineering is more art than science. Improving controllability will make these models more useful and user-friendly.
Environmental Impact: The energy demands of training and deploying large models raise sustainability concerns. Researchers are exploring ways to make models more efficient and environmentally friendly.
Ethics & Bias: There is a risk of generating harmful or biased outputs, misuse, and a need for transparency and safeguards. Addressing ethical issues and ensuring responsible use is essential as these models become more widespread.
Security: Models are vulnerable to adversarial attacks, data leakage, and can be used to create deepfakes. Developing robust defenses and safeguards is crucial to prevent misuse and protect users.
Addressing these challenges will be key to realizing the full potential of Diffusion Transformers and ensuring their responsible and beneficial use.
Notable Models and Research
Below is a table summarizing some of the most influential models and research in the field of diffusion and diffusion-transformer models, with direct links for further reading:
Model | Architecture | Key Results | Year | Link |
DDPM | CNN (U-Net) | Stable, high-quality images | 2020 | |
DALL-E 2 | Diffusion + Transformer | Text-to-image, high fidelity | 2022 | |
Imagen | Diffusion + Transformer | SOTA text-to-image | 2022 | |
DiT | Pure Transformer | SOTA, scalable | 2023 | |
MaskGIT | Masked Transformer | Fast, parallel sampling | 2022 | |
Versatile Diffusion | Multimodal | Text, images, beyond | 2022 | |
Imagen Video | Diffusion + Transformer | High-quality video | 2022 |
The Future of Diffusion Transformers
The future of Diffusion Transformers is bright, with several exciting directions on the horizon:
Faster Sampling: Techniques like DDIM, distillation, and learned samplers are making real-time generation increasingly feasible, opening up new possibilities for interactive and on-demand applications.
More Modalities: Expansion into 3D, audio, interactive media, and AR/VR is underway, broadening the scope of generative AI and enabling richer, more immersive experiences.
Better Control & Interpretability: Advances in prompt engineering, attention visualization, and user-guided generation are making models more controllable and transparent, empowering users to shape outputs more precisely.
Wider Adoption: From film and games to science, education, and accessibility, DTs are poised for widespread impact, transforming industries and enabling new forms of creativity and communication.
Open-Source & Democratization: The release of more models and code is lowering barriers to entry and fostering community-driven innovation, making cutting-edge generative AI accessible to a broader audience.
Regulation & Standards: There is a growing need for ethical guidelines, transparency, accountability, and legal frameworks to ensure responsible development and deployment, protecting users and society from potential harms.
As research and development continue, we can expect Diffusion Transformers to become even more powerful, efficient, and versatile, shaping the future of generative AI and its impact on society.
Conclusion
Diffusion Transformers represent a significant leap forward in generative AI, combining the best of diffusion models (quality, diversity) with the flexibility and scalability of transformers. Their potential is vast, but challenges remain, especially around computational cost, ethics, control, and sustainability.As researchers, developers, and policymakers, it is crucial to work together to ensure responsible development and deployment. The question is not just how DTs will shape creativity and industry, but how they will impact society as a whole in the coming decade. The choices we make today will determine whether these powerful tools are used for the benefit of all, fostering creativity, innovation, and inclusion.